Vorige: Hoe werkt het panel?
Hoe zit het met de statistiek?
De hele korte samenvatting voor wie niks met de getalletjes te maken wil hebben
Door de toewijzing van bier aan panelleden random te doen wordt elk bier steeds door een andere selectie van de panelleden geproefd. Door de verschillende beoordelingen niet op zichzelf te laten staan, maar ook over de verschillende bieren en proefmomenten heen de resultaten samen te nemen, kunnen we met een relatief klein panel toch statistisch betrouwbare resultaten halen. Brouwers krijgen een eenvoudig rapport waarin die statistiek allemaal verstopt is, maar waarvan de resultaten betrouwbaar zijn. Voor elke beoordeling zoals beschreven in "Wat doet dit panel wel en niet?" worden de resultaten in een rapport aan de brouwer teruggegeven, zie de volgende sectie. Ook de panelleden krijgen resultaten van de statistische analyse, maar dan met betrekking tot hun eigen gevoeligheid en eventuele blindheden en ze worden afgezet tegen hun mede-panelleden.
Let op, onderstaande secties zijn vrij technisch, lees als je wilt gerust pas verder vanaf "Tot slot"!
De iets langere variant, voor wie durft
Het uiteindelijke doel is om voor elk ingezonden bier een objectieve beoordeling van de verschillende aspecten die door de brouwer gewenst zijn te krijgen. Met objectief bedoelen we dat de resultaten zoveel mogelijk onafhankelijk worden gemaakt van voorkeuren, gevoeligheden en (smaak-)blindheden bij de verschillende panelleden. We moeten het uiteindelijk doen met waarderingen van proevers, waarbij die eigenschappen van de proever en van het bier in principe niet bekend zijn. We gebruiken statistiek om uit de beoordeling van meerdere bieren door groepen proevers deze eigenschappen van proevers af te leiden, om zo tot objectieve waarderingen van de bieren te komen.
In lesboekjes over smaakpanels en de statistiek die nodig is om er resultaten uit te halen wordt elke beoordeling als op zichzelf staand gezien. Dat wil zeggen dat er bij volgende samples geen rekening wordt gehouden met voorgaande proefresultaten. Dat is natuurlijk zonde. De reden dat je normaliter veel proevers nodig hebt (typisch 15-25) is dat resultaten per proever nogal uiteen kunnen liggen. De een is wat gevoeliger voor bitter en zal dus bitterheid vrij snel hoog inschatten, terwijl een ander altijd zure bieren drinkt en iets pas zuur noemt als het glazuur van je tanden bijna direct oplost. Deze informatie per panellid zit natuurlijk ook in de resultaten van voorgaande proefsessies. Die infomatie nemen we graag mee.
Zulke persoonlijke afwijking van een panelgemiddelde noemen we bias: je schiet altijd wat hoger of wat lager in verschillende elementen van smaakbeleving, dan anderen. Naast bias heeft iedereen een gevoeligheid: je vermogen om verschillen in een bepaalde smaakcomponent ook daadwerkelijk te proeven. Dan is er verder nog de precisie van een proever: gegeven een bekende bias en gevoeligheid is je inschatting van de verschillende smaak- en aromacomponenten in principe duidelijk, maar van beoordeling tot beoordeling zul je altijd een klein beetje kunnen afwijken. Hoe groot dat beetje is, dat is je precisie: een hoge precisie betekent dat je beoordeling altijd heel dicht ligt bij de waarde die hoort bij jouw bias en gevoeligheid voor de betreffende smaakcomponent.
Een klein uitgewerkt voorbeeld
Om duidelijk te maken hoe we daar komen draaien we het nu even om. Stel dat je van een bier de objectieve eigenschappen kent. Hoe gaan proevers dit beoordelen? In het plaatje hieronder zie je een "kunstmatig" voorbeeldje over de beoordeling van zoetigheid. De hoeveelheid zoet die in een bier zit kan van extreem laag tot extreem hoog gaan. Deze is afgebeeld op de horizontale as. De getallen langs de as betekenen niet zoveel, die dienen uiteindelijk alleen om verschillende bieren met elkaar te kunnen vergelijken. Het beoordelende panellid gaat deze op een schaal van 1 tot 5 plaatsen, met alleen hele punten.
Stel dat de zwarte kromme in het linker plaatje de "ideale beoordeling" weergeeft. Zo'n lijn gaat dus niet over 1 bier, maar over een hele reeks bieren met steeds iets meer zoetigheid, en hoe deze dan beoordeeld zouden worden. Vanaf extreem weinig zoetigheid met score 1 moet de zoetigheid boven een bepaalde drempelwaarde uitkomen om een score hoger dan 1 te gaan krijgen. De beoordeling van de zoetigheid stijgt gestaag met de daadwerkelijke zoetheid, totdat deze bijzonder hoog wordt. Vanaf een bepaalde waarde kun je nog meer zoetigheid aantreffen, maar het blijft een score van 5! Meer zoetigheid is dan misschien ook helemaal niet meer te onderscheiden... Het panellid moet deze afronden tot hele punten, wat door het zwarte trappetje wordt weergegeven. Daadwerkelijke beoordelingen kunnen dan een beetje afwijken (iedereen heeft een verschillende precisie), dus afzonderlijke beoordelingen komen niet precies op het trappetje terecht, maar voor bieren met verschillende zoetigheden kunnen die bijvoorbeeld uitkomen op de zwarte puntjes. Wanneer de precisie van de proever lager is, dan komen ze verder van het "ideale trappetje", bijvoorbeeld op de rode puntjes, die over het algemeen wat verder van het trappetje af liggen.
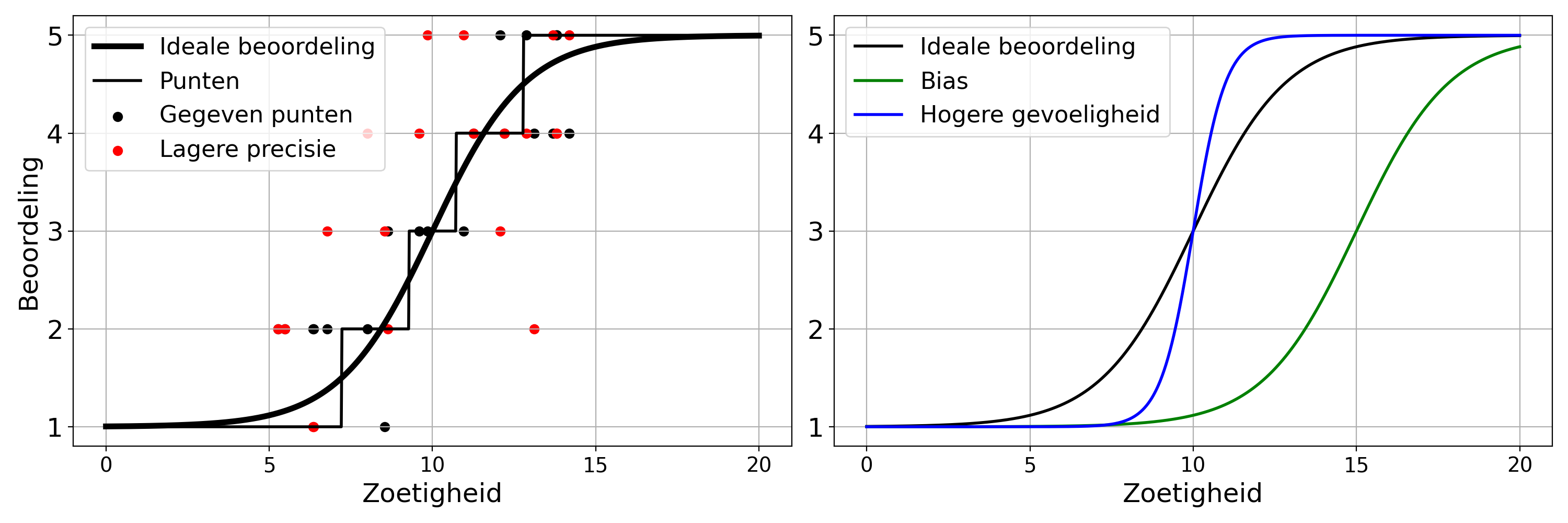
Klik op het plaatje voor een grotere versie! Zoals weergegeven in het rechter plaatje:
- Iemand met een andere bias dan deze proever heeft een patroon dat ten opzichte van deze proever is verschoven naar links of rechts (groene kromme). Ook voor deze proever vallen de de daadwerkelijke beoordelingen natuurlijk weer op puntjes rond een trappetje.
- Iemand met een hogere gevoeligheid heeft een sterkere stijging (en dus een kleiner bereik over welke verschil gemaakt kan worden! Blauwe kromme). Ook voor deze proever vallen de de daadwerkelijke beoordelingen natuurlijk weer op puntjes rond een trappetje.
De kunst van de statistiek is dus nu om voor elk bier te bepalen wat de echte zoetigheid (of andere eigenschap) is, door op basis van alle beoordelingen de bias, gevoeligheid en precisie van elke proever te bepalen, en zo tot een goede bepaling per geproefd bier te kunnen komen (gecorrigeerd voor de biases en gevoeligheden van de afzonderlijke proevers).
Random panels
Wanneer we steeds de bieren ter beoordeling verdelen over andere sub-groepen van het panel, betekent dat dat een bier ook "vitrtueel geproefd" wordt door de rest van het panel. We kennen de onderlinge verschillen in bias, gevoeligheid en precisie, waardoor we op basis van bijvoorbeeld 10 panelleden heel goed kunnen inschatten wat andere panelleden zouden invullen. Dit werkt alleen als alle panelleden genoeg bieren hebben geproefd en beoordeeld in steeds anders samengestelde groepjes uit het totale panel. In technische termen spreken we over informatieuitwisseling. Dat is een ander voordeel van een groot, verspreid panel: door voldoende informatieuitwisseling (door veel bieren door veel verschillende leden van het panel te laten proeven), kun je met minder proefsamples een even betrouwbaar resultaat krijgen als in een vast panel met meer mensen. Kort samengevat zou je kunnen zeggen dat je de panelleden allemaal aan elkaar kunt ijken over alle bieren die ze voor het panel hebben gedronken en dat je die ijking kunt gebruiken om alle beoordelingen te calibreren.
Tot (niet-technisch) slot...
De details licht ik je graag nog verder aan je toe als je daar behoefte aan hebt. Hier is het vooral nog nuttig om te vertellen dat al deze statistiek niet alleen resulteert in betrouwbaardere resultaten voor de beoordeling van het bier, maar ook in een nauwkeurig inzicht in de eigenschappen van elke proever in het panel. Voor de proever kan dat heel erg interessant zijn! Voor een overzicht van de voordelen voor de proever, zie "Waarom zou een proever meedoen?".
Volgende: Wat krijgt de brouwer terug?